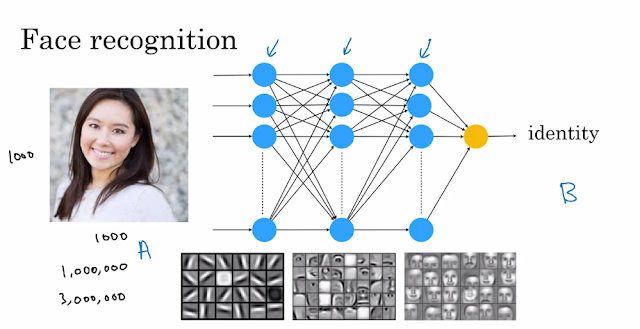
TensorFlow 之 Mane 个人用笔记(一)

training_images = training_images / 255.0 test_images = test_images / 255.0 Before you trained, you normalized the data, going from values that were 0-255 to values that were 0-1. What would be the impact of removing that? Why should we normalize data for deep learning in Keras? model = tf.keras.models.Sequential([ #tf.keras.layers.Flatten(), tf.keras.layers.Dense(64, activation=tf.nn.relu), tf.keras.layers.Dense(10, activation=tf.nn.softmax)]) What would happen if you remove the Flatten() layer. Why do you think that's the case? You get an error about the shape of the data. It may seem vague right now, but it reinforces the rule of thumb that the first layer in your network should be the same shape as your data. Right now our data is 28x28 images, and 28 layers of 28 neurons would be infeasible, so it makes more sense to 'flatten' that 28,28 into a 784x1. Instead of wriitng all the code to ...