TensorFlow 官方自然语言处理系列 笔记
前言
个人整理的笔记,如有错误可以评论区更正下喵,毕竟本喵正在学习,强烈建议在看这篇文章之前先去看看官方视频。
视频
TensorFlow 官方自然语言处理系列视频 (英文字幕,约40分钟)
Natural Language Processing - Tokenization (NLP Zero to Hero - Part 1)
有些人使用每一个单词里面的字母换成 ASCII 码然后扔进去 NN 处理,但是对于 NN 来说,得到了一堆只是相同的但顺序不同的 ASCII 码,这样 NN 很难理解一个词的感情,所以这个时候,需要把一个单词变成编号即可。[Colab]
word_docs 和 word_counts 。
那么问题来了,为什么 dog 和 dog! 元素是一样的呢?其实在处理的过程中,Tokenizer 会很智能的把每一个大小写或者标题符号给转换或者省略掉,当然 loves 和 love 也看成是一样的。
参考
Sequencing - Turning sentences into data (NLP Zero to Hero - Part 2)
当统计好单词以后,怎么把句子变为一串编码呢?其实只需要插入多一句就可以让句子变成编码了。[Colab]
oov_token ,这意味着把其他不认识的单词转化成你设置的单词。
<oov> ,这么做当然会损失一些单词,但前提是已经知道这个单词对 NN 影响不大,这么做至少句子的长度可以保持正确。
那怎么处理长度不同的句子呢?其实一个最简单的处理方法是把一些长度不够的句子用 0 填充。
'pre' 和 'post' 。
参考
Training a model to recognize sentiment in text (NLP Zero to Hero - Part 3)
现在已经了解了怎么简单的对句子进行预处理。下面的例子将创建 NN ,并将一堆数据喂入 NN 里面。可以从这里下载一堆训练的数据集。
article_link 、headline 和 is_sarcastic ,为了更简单的处理 json 文件,可以载入 python 的 json 模块进行更快的处理。
(喵?) ,要划分训练集和测试集。训练的时候,X label 和 Y label 要分开。
现在问题来了,我给你一个单词,去判断坏 和 好 ,但是有一些单词比如 Not bad 又不是特别好,Meh 也不是特别坏,这个时候也不能说完全好或坏,怎么分类呢?其实可以把它换成向量 Embedding 。上面已经有10000个index 的单词,每一句句子长度为16个词语。
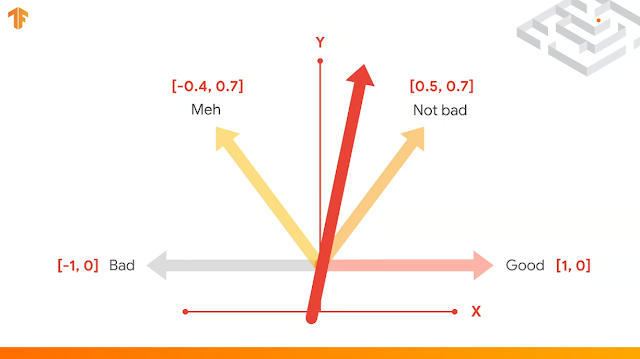
现在我说一个句子,这个句子里面包含,"Not bad, a bit meh." 现在 NN 发现一个句子里面出现了两个词语,该怎么办?其实很简单,只要把他们加起来就好了。
参考
ML with Recurrent Neural Networks (NLP Zero to Hero - Part 4)
在上面几个小节中,你看到了如何创建一个 NN 并且喂入到这个 NN 里,但是人讲话总是有顺序的,如果一个词语的顺序对调了,这句话的意思也不一样。对于传统的 NN 只能够判断当前句子好与坏,如果用来判断下一个词语是什么,但是结果会非常不准,所以预测的时候还要考虑这句话的顺序。我们说话是有顺序的,如果你需要训练一个 NN 来预测下一个字会出现什么,可以使用RNN 。
首先介绍 RNN ,也就是递归神经网络,在开始之前请您看这个视频 和参考递归神经网络(RNN)简介 。现在来看一个句子:
相信大家第一个反应也许是 sky,通过上面的简单介绍,可以看到它第一个单词开始递归计算到最后一个单词,最后再预测你想要的单词。
Long Short-Term Memory for NLP (NLP Zero to Hero - Part 5)
现在再来看另一个句子:
你可能觉得是 Irish 但事实上是 Gaelic,因为 keyword 是 lreland ,从而推出 Gaelic。记住现在一直在研究递归神经网络,通过上下文的神经元,他可以学习一些词语,仅仅是上下几个单词而已,如果 keyword 和预测的词语距离太长,预测的结果就会不准 ,这就是 RNN 的坏处。这里有个比喻:RNN 就像人和人传话,前几个还可以表达的正确意思,传的人多了,最后到了后面就变味了。
如果单纯的使用 RNN ,还会有几率出现致命的问题:梯度消失和梯度爆炸 ,这个时候就可以使用 RNN 的升级版 LSTM RNN 来改善这个问题,在了解 LSTM RNN 之前请您观看这个介绍视频 和补充视频 。
LSTM RNN 引用了一个类似于状态,可以随便跨越前面出现过的每个递归。它可以得知 lreland 用的是 Gaelic 的语言,不仅是从前面开始递归计算到后面预测,或者是反向的都可以。
现在使用 LSTM 和 分类器,与往常一样,只是在分类完成之后加一行 LSTM 层,这还需要一个数字参数作为隐藏节点的数量,这也是输出的维数。
Training an AI to create poetry (NLP Zero to Hero - Part 6)
在这个示例中将会演示,给一个不完整的歌词,让AI去模仿一位艺人去填充单词。这位艺人之前写过的歌词数据集可以在这里下载。[Colab]
现在拿到一个句子,并且编码化后,需要将其拆分,然后append到一个列表里面。
假设一行歌词编码化后是 [4 2 66 8 67 68 69 70] ,我需要得到一个这样的数组:

提取 X 和 Y :
(喵?)
总结:
TensorFlow官方教程简明易懂,适合大多数人上手,如果有错误的地方欢迎在评论区喵一声。
另外,禁止转载,只能引用连接。
个人整理的笔记,如有错误可以评论区更正下喵,毕竟本喵正在学习,强烈建议在看这篇文章之前先去看看官方视频。
视频
TensorFlow 官方自然语言处理系列视频 (英文字幕,约40分钟)
Natural Language Processing - Tokenization (NLP Zero to Hero - Part 1)
有些人使用每一个单词里面的字母换成 ASCII 码然后扔进去 NN 处理,但是对于 NN 来说,得到了一堆只是相同的但顺序不同的 ASCII 码,这样 NN 很难理解一个词的感情,所以这个时候,需要把一个单词变成编号即可。[Colab]
from tensorflow.keras.preprocessing.text import Tokenizer
sentences = [
'i love my dog',
'I, love my cat',
'You love my dog!'
]
tokenizer = Tokenizer(num_words = 100)
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
print(word_index)
{'love': 1, 'my': 2, 'i': 3, 'dog': 4, 'cat': 5, 'you': 6}那么问题来了,为什么 dog 和 dog! 元素是一样的呢?其实在处理的过程中,Tokenizer 会很智能的把每一个大小写或者标题符号给转换或者省略掉,当然 loves 和 love 也看成是一样的。
参考
Sequencing - Turning sentences into data (NLP Zero to Hero - Part 2)
当统计好单词以后,怎么把句子变为一串编码呢?其实只需要插入多一句就可以让句子变成编码了。[Colab]
sentences = [
'I love my dog',
'I love my cat',
'You love my dog!',
'Do you think my dog is amazing?'
]
sequences = tokenizer.texts_to_sequences(sentences)
>>> [[5, 3, 2, 4], [5, 3, 2, 7], [6, 3, 2, 4], [8, 6, 9, 2, 4, 10, 11]]
test_data = [
'i really love my dog',
'my dog loves my manatee'
]
test_seq = tokenizer.texts_to_sequences(test_data)
>>> [[4,2,1,3],[1,3,1]] tokenizer = Tokenizer(num_words = 100, oov_token="<oov>" )
>>> {'<oov>': 1 , 'my': 2, 'love': 3, 'dog': 4, 'i': 5, 'you': 6, 'cat': 7, 'do': 8, 'think': 9, 'is': 10, 'amazing': 11}那怎么处理长度不同的句子呢?其实一个最简单的处理方法是把一些长度不够的句子用 0 填充。
from tensorflow.keras.preprocessing.sequence import pad_sequences
padded = pad_sequences(test_seq, maxlen=10)
>>> [[0 0 0 0 0 5 1 3 2 4][0 0 0 0 0 2 4 1 2 1]]
padded = pad_sequences(test_seq,padding='post', maxlen=10)padded = pad_sequences(test_seq,padding='post',truncating='post', maxlen=10)参考
Training a model to recognize sentiment in text (NLP Zero to Hero - Part 3)
现在已经了解了怎么简单的对句子进行预处理。下面的例子将创建 NN ,并将一堆数据喂入 NN 里面。可以从这里下载一堆训练的数据集。
{"article_link": "https://www.huffingtonpost.com/entry/versace-black-code_us_5861fbefe4b0de3a08f600d5", "headline": "former versace store clerk sues over secret 'black code' for minority shoppers", "is_sarcastic": 0},
{"article_link": "https://www.huffingtonpost.com/entry/roseanne-revival-review_us_5ab3a497e4b054d118e04365", "headline": "the 'roseanne' revival catches up to our thorny political mood, for better and worse", "is_sarcastic": 0},
{"article_link": "https://local.theonion.com/mom-starting-to-fear-son-s-web-series-closest-thing-she-1819576697", "headline": "mom starting to fear son's web series closest thing she will have to grandchild", "is_sarcastic": 1}
with open("sarcasm.json", 'r') as f:
datastore = json.load(f)
sentences = []
labels = []
for item in datastore:
sentences.append(item['headline'])
labels.append(item['is_sarcastic'])
training_size = 20000
training_sentences = sentences[0:training_size]
testing_sentences = sentences[training_size:]
training_labels = labels[0:training_size]
testing_labels = labels[training_size:]
现在完成了所有数据的预处理。tokenizer = Tokenizer(num_words=10000, oov_token="<oov>")tokenizer.fit_on_texts(training_sentences) word_index = tokenizer.word_index training_sequences = tokenizer.texts_to_sequences(training_sentences) training_padded = pad_sequences(training_sequences, maxlen=100, padding='post', truncating='post') testing_sequences = tokenizer.texts_to_sequences(testing_sentences) testing_padded = pad_sequences(testing_sequences, maxlen=100, padding='post', truncating='post')
现在问题来了,我给你一个单词,去判断
tf.keras.layers.Embedding(10000, 16, input_length=100)
现在我说一个句子,这个句子里面包含,"Not bad, a bit meh." 现在 NN 发现一个句子里面出现了两个词语,该怎么办?其实很简单,只要把他们加起来就好了。
tf.keras.layers.GlobalAveragePooling1D()model = tf.keras.Sequential([
tf.keras.layers.Embedding(10000, 16, input_length=100),
tf.keras.layers.GlobalAveragePooling1D(),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, 100, 16) 160000
_________________________________________________________________
global_average_pooling1d_1 ( (None, 16) 0
_________________________________________________________________
dense_2 (Dense) (None, 24) 408
_________________________________________________________________
dense_3 (Dense) (None, 1) 25
=================================================================
Total params: 160,433
Trainable params: 160,433
Non-trainable params: 0
_________________________________________________________________
num_epochs = 30
history = model.fit(training_padded, training_labels, epochs=num_epochs, validation_data=(testing_padded, testing_labels), verbose=2)
sentence = ["granny starting to fear spiders in the garden might be real", "game of thrones season finale showing this sunday night"]
sequences = tokenizer.texts_to_sequences(sentence)
padded = pad_sequences(sequences, maxlen=100, padding='post', truncating='post')
print(model.predict(padded))
>>> [[9.940163e-01][6.710888e-05]]
参考
- T81-558: Applications of Deep Neural Networks
- NLP词嵌入Word embedding实战项目 (tensorflow2.0官方教程翻译)
- tensorflow中的Embedding操作详解
ML with Recurrent Neural Networks (NLP Zero to Hero - Part 4)
在上面几个小节中,你看到了如何创建一个 NN 并且喂入到这个 NN 里,但是人讲话总是有顺序的,如果一个词语的顺序对调了,这句话的意思也不一样。对于传统的 NN 只能够判断当前句子好与坏,如果用来判断下一个词语是什么,但是结果会非常不准,所以预测的时候还要考虑这句话的顺序。我们说话是有顺序的,如果你需要训练一个 NN 来预测下一个字会出现什么,可以使用
首先介绍 RNN ,也就是递归神经网络,在开始之前请您看
Today the weather is gorgeous and I see a beautiful blue [...]
相信大家第一个反应也许是 sky,通过上面的简单介绍,可以看到它第一个单词开始递归计算到最后一个单词,最后再预测你想要的单词。
Long Short-Term Memory for NLP (NLP Zero to Hero - Part 5)
现在再来看另一个句子:
I lived in lreland, so at school they made me learn how to speak [...]
你可能觉得是 Irish 但事实上是 Gaelic,因为 keyword 是 lreland ,从而推出 Gaelic。记住现在一直在研究递归神经网络,通过上下文的神经元,他可以学习一些词语,
如果单纯的使用 RNN ,还会有几率出现致命的问题:
LSTM RNN 引用了一个类似于状态,可以随便跨越前面出现过的每个递归。它可以得知 lreland 用的是 Gaelic 的语言,不仅是从前面开始递归计算到后面预测,或者是反向的都可以。
现在使用 LSTM 和 分类器,与往常一样,只是在分类完成之后加一行 LSTM 层,这还需要一个数字参数作为隐藏节点的数量,这也是输出的维数。
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional (tf.keras.layers.LSTM(64) ),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 64) 64000
_________________________________________________________________
bidirectional_2 (Bidirection (None, 128) 66048
_________________________________________________________________
dense_2 (Dense) (None, 64) 8256
_________________________________________________________________
dense_3 (Dense) (None, 1) 65
=================================================================
Total params: 138,369
Trainable params: 138,369
Non-trainable params: 0
_________________________________________________________________
model = tf.keras.Sequential([
tf.keras.layers.Embedding(tokenizer.vocab_size, 64),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64,return_sequences=True )),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(32)),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
Training an AI to create poetry (NLP Zero to Hero - Part 6)
在这个示例中将会演示,给一个不完整的歌词,让AI去模仿一位艺人去填充单词。这位艺人之前写过的歌词数据集可以在这里下载。[Colab]
tokenizer = Tokenizer()
data = open('/tmp/irish-lyrics-eof.txt').read()
corpus = data.lower().split("\n")
tokenizer.fit_on_texts(corpus)
total_words = len(tokenizer.word_index) + 1
现在拿到一个句子,并且编码化后,需要将其拆分,然后append到一个列表里面。
假设一行歌词编码化后是 [4 2 66 8 67 68 69 70] ,我需要得到一个这样的数组:
[4 2]
[4 2 66]
[4 2 66 8]
[4 2 66 8 67]
[4 2 66 8 67 68]
[4 2 66 8 67 68 69]
[4 2 66 8 67 68 69 70]
input_sequences = []
for line in corpus:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
[0 0 0 0 0 0 0 0 0 0 4 2]
[0 0 0 0 0 0 0 0 0 4 2 66]
[0 0 0 0 0 0 0 0 4 2 66 8]
[0 0 0 0 0 0 0 4 2 66 8 67]
[0 0 0 0 0 0 4 2 66 8 67 68]
[0 0 0 0 0 4 2 66 8 67 68 69]
[0 0 0 0 4 2 66 8 67 68 69 70]
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))
print(input_sequences)

提取 X 和 Y :
xs, labels = input_sequences[:,:-1],input_sequences[:,-1]ys = tf.keras.utils.to_categorical(labels, num_classes=total_words)model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(Bidirectional(LSTM(150)))
model.add(Dense(total_words, activation='softmax'))
adam = Adam(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=adam, metrics=['accuracy'])
print (model.summary())
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, 15, 100) 269000
_________________________________________________________________
bidirectional_2 (Bidirection (None, 300) 301200
_________________________________________________________________
dense_2 (Dense) (None, 2690) 809690
=================================================================
Total params: 1,379,890
Trainable params: 1,379,890
Non-trainable params: 0
_________________________________________________________________
history = model.fit(xs, ys, epochs=100 , verbose=1)seed_text = "I've got a bad feeling about this"
next_words = 100
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1 , padding='pre')
predicted = model.predict_classes(token_list, verbose=0)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
print(seed_text)
I've got a bad feeling about this very satisfaction like back a young strength had gone my love is gone can love again be irishmen can love return gone love gone my love i might love gone love gone and bride but destiny vow love again ive ended thee love gone away gone my love side i love til bride away oer side love love my love gone love gone your love gone your eyes gone and gone love gone love gone my love and gone love gone your tags gone away now love and love gone gone love gone my love and gone i can gone
总结:
TensorFlow官方教程简明易懂,适合大多数人上手,如果有错误的地方欢迎在评论区喵一声。
另外,禁止转载,只能引用连接。
Comments
Post a Comment