AI概论 第二周笔记 - Building AI Projects
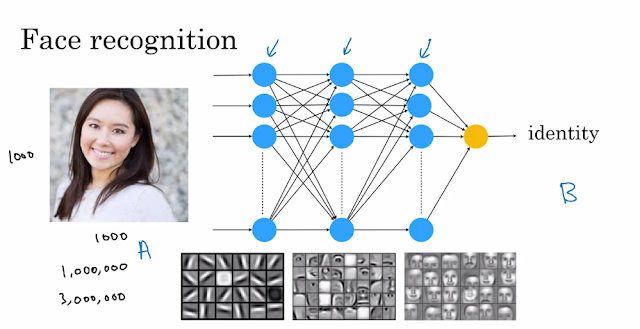
前言 续上一个星期的内容, 禁止转载 。 Week 2 Introduction 在这一篇文章中,会介绍启动一个AI项目需要做什么,AI的流程是什么,怎么去选择一个AI项目,如何组织数据和建立团队,无论对你自己或是和朋友一起,亦或是企业里更大规模的队伍,都是重要的。 Workflow of a machine learning project 机器学习可以学习从输入到输出,或 A-->B 的过程。 第一步是收集数据:现在那语音助手举个例子,比如苹果的siri,你得到处走然后让人们来说这个词'siri' ,然后你把这些语音记录下来,同时也需要收集其他的词 例如'你好'等很多其他的词,并且录音下来。当你收集了非常多音频数据 也就是收集了很多不同人说 'siri' 或其他词语的语音后就可以开始训练数据了。 第二步就是训练模型,就是说你需要利用一个机器学习算法 来学习从输入到输出,或者是A到B的映射,这里输入A就是一段上面收集的语音。这个时候团队会尝试第一次建立模型和训练,如果一次尝试的效果不好就需要尝试很多次。(在人工智能领域,叫做反复迭代。)直到模型看起来足够好为止。 第三步就是把训练好的模型发放给任何人用,让任何人去评估这个训练好的模型。如果有人觉得不好用,或者有人说siri之后 NN 没反应,这个时候就要维护和更新下 NN (比如英式口音和美式口音)。 Workflow of a data science project 和机器学习项目不同,可以从数据科学那里得到改进的行动和观点。这些观点可能会让你的采取不同的行动,所以数据科学项目与机器学习的工作流程不同。 如果你在运营一个卖咖啡杯的电子商务平台 或者是在线购物网站,所以当一个用户从你这购买咖啡杯时,他们常常需要经过一系列步骤。 首先,他们将访问你的网站,浏览不同的马克杯,然后他们点进某个产品的详情页面,他们把商品放入购物车,进入支付界面,最终他们将支付订单。在这个过程中可以通过用户点击记录一份日志。 第2步是分析数据,你的数据团队可能会想出很多会影响销售因素,例如,数据团队也许 会认为海外顾客因为国际运费太高而被吓退,这可以解释为什么很多人虽然 点进了支付页面,但是最终没有下单。如果真是这样,那么你可能会考虑是否把部分运...